 by
by The open-source AI world is buzzing with Meta’s surprise December drop of Llama 3.3 70B, and this isn’t your typical corporate PR hype train. The local AI community is legitimately excited because this thing is actually running on people’s machines – and running well.
“It’s the first time after testing I really think we finally have a very strong model available free,” reports one enthusiastic r/LocalLLaMA user. Another adds, “Reasoning over complex tasks is markedly better.” The hype seems real this time.

The Good Stuff
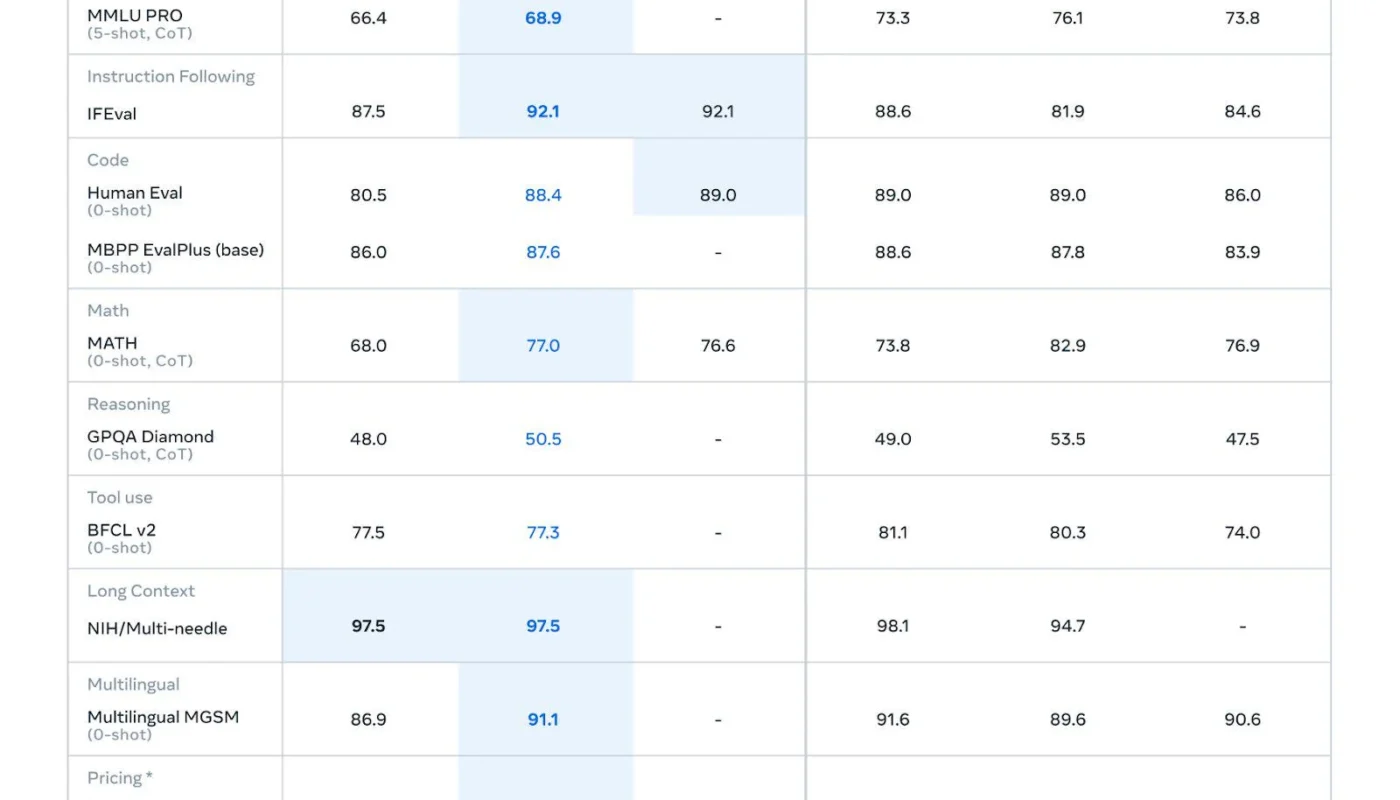
Early testers are finding some wild improvements. One physics nerd discovered it’s the first LLM to properly understand and explain the Everett interpretation in quantum mechanics (weird flex but ok). The coding capabilities got a serious buff too – it’s nailing 88.4% on HumanEval, up from 80.5%. Though some devs note it still gets cranky when debugging.
The Chinese Model Drama
Here’s where it gets spicy – the AI community immediately called out Qwen’s absence from Meta’s benchmarks. “As usual, Qwen comparison is conspicuously absent,” noted multiple users, sparking heated debates about whether Qwen 2.5 72B might still be the big brain champion. Some suspect it’s deliberate avoidance of drawing attention to Chinese models’ capabilities. One Redditor quipped, “Whatever you do, don’t look at the hunyan video model that’s gonna support multi-gpu soon.”
The Real Heroes: Community Quantization
The true MVPs are already pushing out optimized versions. Our boy Unsloth dropped everything from 2-bit to 16-bit GGUF flavors almost immediately. Bartowski’s pushing out IMatrix versions, and the LMStudio crew isn’t far behind. Want to run this beast locally? Take your pick based on your hardware:
- Full 16-bit: Hope you own a data center
- 8-bit: Still needs serious GPU power
- 4-bit: Sweet spot for most home labs
- 3-bit and 2-bit: For the brave souls with limited VRAM
Context is King
The 128K context window is a big deal because it actually works without jumping through hoops. While Qwen technically matches this, users report the Llama implementation is more straightforward. “Llama has never had this issue,” noted one user comparing it to Qwen’s YARN requirements.
Hardware Reality Check
Let’s be real – you’ll need some decent hardware to run this. The community’s already experimenting with different quantization levels to make it more accessible. Some madlads are even running it on consumer GPUs with aggressive quantization, though you might want to keep a fire extinguisher handy.
The Bad News
Pour one out for the small model gang – no 7B or 13B versions coming. “Release the 33B you cowards,” demanded one user, while another suggested, “Now do the same but with a 3b model😀.” Some optimists are suggesting knowledge distillation might save the day, but don’t hold your breath.
What’s Actually Better?
- Math skills got a serious upgrade (77.0% vs old 68.0%)
- Reasoning improved across the board
- Better at following instructions
- Actually understands complex topics
- Multilingual capabilities enhanced
- Code generation is notably better
- Tool use implementation is cleaner
Community Tools & Implementations
The ecosystem is exploding with options:
- Llama.cpp support already rolling
- LM Studio integration
- Various GGUF quantizations
- ExLlamaV2 versions incoming
- Multiple optimization projects underway
Some Spicy
Community Takes: “my condolences to 405b” – Reddit user celebrating the efficiency gains “It certainly has a better understanding of physics” – AI enthusiast testing complex scenarios “Still wins in 6/10 categories” – 405B defender noting it’s not completely obsolete “Release the 33B you cowards” – The eternal cry for smaller models
What’s Next?
While some are already hyped about Llama 4, the community seems genuinely stoked about what they can do with 3.3 right now. It’s hitting a sweet spot between capability and runability that we haven’t seen before in the open-source world.
The Local AI Revolution Continues
Whether you’re a hardcore AI enthusiast with a rack of A100s or just someone with a decent gaming GPU hoping to run some experiments, Llama 3.3 70B represents another big step toward bringing serious AI capabilities to local computing. Now excuse me while I go figure out how to explain to my partner why we need another GPU.
Pro Tip:
Keep an eye on the community quantization efforts – they’re the real heroes making this accessible to mere mortals without corporate budgets. And maybe wait a few days before downloading to let the optimization wizards work their magic.
Time to free up some disk space and pray to the VRAM gods – the new toy is here, and it’s actually pretty awesome.
